随机森林介绍
随机森林(Random Forest)作为一种比较新机器学习方法,近年来在界内的关注度与受 欢迎程度得到逐步提升。经典的机器学习模型是神经网络,其预测精确,但计算量也大。 上世纪 80 年代,决策树算法首次出现,通过反复二分数据进行分类或回归,计算量大大 降低。2001 年 Breiman 在此基础提出一种新的算法,这一算法是由多个随机子集生成决 策树的实例组成,故我们将其形象地称为“随机森林”。下面我们将从决策树入手,一起 逐步探索随机森林的奥秘
相关概念
分类器:分类器就是给定一个样本的数据,判定这个样本属于哪个类别的算法。例如在期货涨跌预测中,我们认为前一天的交易量和收盘价对于第二天的涨跌是有影响的,那么分类器就是通过样本的交易量和收盘价预测第二天的涨跌情况的算法。
分裂:在决策树的训练过程中,需要一次次的将训练数据集分裂成两个子数据集,这个过程就叫做分裂。
特征:在分类问题中,输入到分类器中的数据叫做特征。以上面的期货涨跌预测问题为例,特征就是前一天的交易量和收盘价。
待选特征:在决策树的构建过程中,需要按照一定的次序从全部的特征中选取特征。待选特征就是在目前的步骤之前还没有被选择的特征的集合。例如,全部的特征是 ABCDE,第一步的时候,待选特征就是ABCDE,第一步选择了C,那么第二步的时候,待选特征就是ABDE。
分裂特征:接待选特征的定义,每一次选取的特征就是分裂特征。例如,在上面的例子中,第一步的分裂特征就是C。因为选出的这些特征将数据集分成了一个个不相交的部分,所以叫它们分裂特征。
决策树
在了解随机森林之前,我们需要先了解一下决策树。决策树是一种基本的分类器,一般是将特征分为两类(决策树也可以用来回归,不过本文中暂且不表),根据一系列的特征,依次进行筛选,得到最后“是”或“否”的决策结果。构建好的决策树呈树形结构,可以认为是if-then规则的集合,主要优点是模型具有可读性,分类速度快。
我们用选择量化工具的过程形象的展示一下决策树的构建。假设现在要选择一个优秀的量化工具来帮助我们更好的炒股,怎么选呢?
第一步:看看工具提供的数据是不是非常全面,数据不全面就不用。
第二步:看看工具提供的API是不是好用,API不好用就不用。
第三步:看看工具的回测过程是不是靠谱,不靠谱的回测出来的策略也不敢用啊。
第四步:看看工具支不支持模拟交易,光回测只是能让你判断策略在历史上有用没有,正式运行前起码需要一个模拟盘吧。
这样,通过将“数据是否全面”,“API是否易用”,“回测是否靠谱”,“是否支持模拟交易”将市场上的量化工具贴上两个标签:“使用”和“不使用”。
上面就是一个决策树的构建,逻辑可以用下图表示:
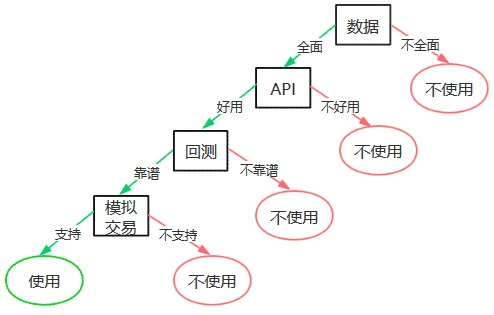
在上图中,方框中的 “数据”、“API”、“回测”、“模拟交易” 就是这个决策树中的特征。如果特征的顺序不同,同样的数据集构建出的决策树也可能不同。特征的顺序分别是 “数据”、“API”、“回测”、“模拟交易”。如果我们选取特征的顺序分别是 “数据”、“模拟交易”、“API”、“回测”,那么构建的决策树就完全不同了。
可以看到,决策树的主要工作,就是选取特征对数据集进行划分,最后把数据贴上两类不同的标签。如何选取最好的特征呢?还用上面选择量化工具的例子:假设现在市场上有100个量化工具作为训练数据集,这些量化工具已经被贴上了 “可用” 和 “不可用” 的标签。
我们首先尝试通过 “API是否易用” 将数据集分为两类;发现有90个量化工具的API是好用的,10个量化工具的API是不好用的。而这90个量化工具中,被贴上 “可以使用” 标签的占了40个,“不可以使用” 标签的占了50个。那么,通过 “API是否易用” 对于数据的分类效果并不是特别好。因为,给你一个新的量化工具,即使它的API是易用的,你还是不能很好贴上 “使用” 的标签。
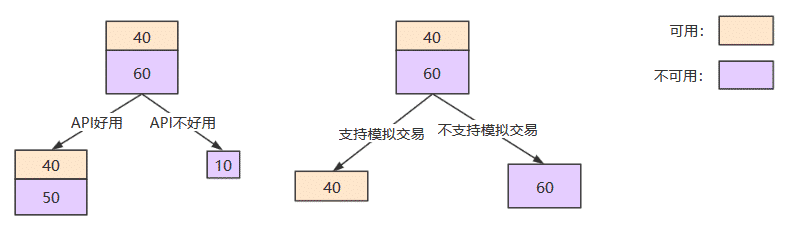
再假设,同样的100个量化工具,通过 “是否支持模拟交易” 可以将数据集分为两类,其中一类有40个量化工具数据,这40个量化工具都支持模拟交易,都最终被贴上了 “使用” 的标签,另一类有60个量化工具,都不支持模拟交易,也都最终被贴上了 “不使用” 的标签。如果一个新的量化工具支持模拟交易,你就能判断这个量化工具是可以使用。我们认为,通过 “是否支持模拟交易” 对于数据的分类效果就很好。
在现实应用中,数据集往往不能达到上述 “是否支持模拟交易” 的分类效果。所以我们用不同的准则衡量特征的贡献程度。主流准则的列举3个:ID3算法(J. Ross Quinlan于1986年提出),采用信息增益最大的特征;C4.5算法(J. Ross Quinlan于1993年提出)采用信息增益比选择特征;CART算法(Breiman等人于1984年提出)利用基尼指数最小化准则进行特征选择。
随机森林
随机森林就是通过集成学习的思想将多棵树集成的一种算法,它的基本单元是决策树,而它的本质属于机器学习的一大分支——集成学习(Ensemble Learning)方法。随机森林的名称中有两个关键词,一个是 “随机”,一个就是 “森林” 。“森林” 我们很好理解,一棵叫做树,那么成百上千棵就可以叫做森林了,这样的比喻还是很贴切的,其实这也是随机森林的主要思想——集成思想的体现。“随机” 的含义我们会在下边部分讲到。
其实从直观角度来解释,每棵决策树都是一个分类器(假设现在针对的是分类问题)。我们要将一个输入样本进行分类,我们需要将输入样本输入到每棵树中进行分类。那么对于一个输入样本,N棵树会有N个分类结果。打个形象的比喻:森林中召开会议,讨论某个动物到底是老鼠还是松鼠,每棵树都要独立地发表自己对这个问题的看法,也就是每棵树都要投票。该动物到底是老鼠还是松鼠,要依据投票情况来确定,获得票数最多的类别就是森林的分类结果。森林中的每棵树都是独立的,99.9%不相关的树做出的预测结果涵盖所有的情况,这些预测结果将会彼此抵消。少数优秀的树的预测结果将会超脱于芸芸“噪音”,做出一个好的预测。随机森林集成了所有的分类投票结果,将投票次数最多的类别指定为最终的输出,这就是随机森林的 Bagging 思想。
有了树我们就可以分类了,但是森林中的每棵树是怎么生成的呢?
每棵树的按照如下规则生成:
- 如果训练集大小为N,对于每棵树而言,随机且有放回地从训练集中的抽取N个训练样本(这种采样方式称为bootstrap sample方法),作为该树的训练集;
从这里我们可以知道:每棵树的训练集都是不同的,而且里面包含重复的训练样本(理解这点很重要)。
为什么要随机抽样训练集?
如果不进行随机抽样,每棵树的训练集都一样,那么最终训练出的树分类结果也是完全一样的,这样的话完全没有bagging的必要;
为什么要有放回地抽样?
如果不是有放回的抽样,那么每棵树的训练样本都是不同的,都是没有交集的,这样每棵树都是”有偏的”,都是绝对”片面的”(当然这样说可能不对),也就是说每棵树训练出来都是有很大的差异的;而随机森林最后分类取决于多棵树(弱分类器)的投票表决,这种表决应该是”求同”,因此使用完全不同的训练集来训练每棵树这样对最终分类结果是没有帮助的,这样无异于是”盲人摸象”。 - 如果每个样本的特征维度为M,指定一个常数m<<M,随机地从M个特征中选取m个特征子集,每次树进行分裂时,从这m个特征中选择最优的;
- 每棵树都尽最大程度的生长,并且没有剪枝过程。
一开始我们提到的随机森林中的“随机”就是指的这里的两个随机性。两个随机性的引入对随机森林的分类性能至关重要。由于它们的引入,使得随机森林不容易陷入过拟合,并且具有很好得抗噪能力(比如:对缺省值不敏感)。
随机森林分类效果(错误率)与两个因素有关:
第一: 森林中任意两棵树的相关性:相关性越大,错误率越大;
第二: 森林中每棵树的分类能力:每棵树的分类能力越强,整个森林的错误率越低。
减小特征选择个数m,树的相关性和分类能力也会相应的降低;增大m,两者也会随之增大。所以关键问题是如何选择最优的m(或者是范围),这也是随机森林唯一的一个参数。
python代码实现
样本数据
特征是用收盘价数据计算的SMA、WMA、MOM指标。
训练样本是从n天以前(n为可设置的参数)到当前交易日(或回测到的当天)的每组指标;每交易日的指标对应的标签是下一交易日的涨跌情况,涨了为True,跌了为False。
测试样本是当前交易日的三个指标。
在输入测试样本并得到测试结果后(即涨跌情况),将预测得到的标签与测试样本真实涨跌对比,即可判断预测分类的正确与否。
(注:因为每个交易日收盘时预测下一个交易日的涨跌情况,所以其预测结果的正确与否需要在下一个交易日收盘时才能判定。因此回测的起始日不能用于判定预测结果正确性。)
实现工具
本代码使用TiaQin Python SDK获取数据,使用sklearn预测以及用talib计算指标。
sklearn中文文档:http://sklearn.apachecn.org/#/
免费期货模拟、实盘天勤量化软件:https://www.shinnytech.com/tianqin/
talib文档:https://mrjbq7.github.io/ta-lib/doc_index.html
代码实现逻辑
- 在回测中的每一个交易日:
- 获取计算数据(训练数据及预测数据)。
- 将训练数据输入sklearn的随机森林进行训练,然后输入预测数据得到预测结果,保存此结果。
- 根据获得的预测结果进行交易(如果预测结果为涨,则买入看涨;如果预测结果为跌,则卖出看跌)。
- 回测结束后:
处理计算数据,根据每天的收盘价计算其真实涨跌情况,判断保存的预测结果的正确率。
代码回测运行:
- 回测参数:
回测日期:2018.7.2 —— 2018.9.26
合约代码:SHFE.ru1811
每次交易手数:10手
随机森林里决策树的数目:30
建立决策树时数据是否有放回抽样:是(True)
初始账户资金:100万(默认值)
回测时盘口行情quote的更新频率:和K线分钟线的更新频率一致 - 回测结果
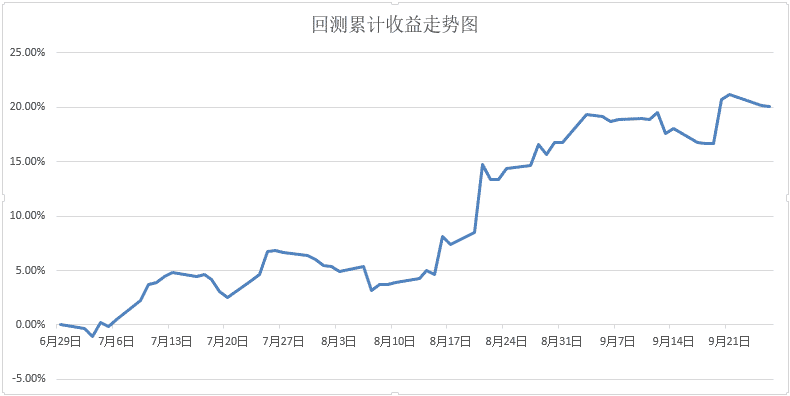
随机森林回测结果 合约代码 收益率 风险度 最大回撤 年化夏普率 SHFE.ru1811 20.10% 11.04% 3.46% 3.7588 回测预测准确率:59.03%
回测结果显示:

回测每日累积收益走势图:

天勤中策略源代码:
#!/usr/bin/env python # -*- coding: utf-8 -*- __author__ = 'limin' import pandas as pd import datetime from contextlib import closing from tqsdk import TqApi, TqBacktest, BacktestFinished, TargetPosTask from tqsdk.tafunc import sma, ema2, trma from sklearn.ensemble import RandomForestClassifier pd.set_option('display.max_rows', None) # 设置Pandas显示的行数 pd.set_option('display.width', None) # 设置Pandas显示的宽度 ''' 应用随机森林对某交易日涨跌情况的预测(使用sklearn包) 参考:https://www.joinquant.com/post/1571 注: 该示例策略仅用于功能示范, 实盘时请根据自己的策略/经验进行修改 ''' symbol = "SHFE.ru1811" # 交易合约代码 close_hour, close_minute = 14, 50 # 预定收盘时间(因为真实收盘后无法进行交易, 所以提前设定收盘时间) def get_prediction_data(klines, n): """获取用于随机森林的n个输入数据(n为数据长度): n天中每天的特征参数及其涨跌情况""" close_prices = klines.close[- 30 - n:] # 获取本交易日及以前的收盘价(此时在预定的收盘时间: 认为本交易日已收盘) # 计算所需指标 sma_data = sma(close_prices, 30, 0.02)[-n:] # SMA指标, 函数默认时间周期参数:30 wma_data = ema2(close_prices, 30)[-n:] # WMA指标 mom_data = trma(close_prices, 30)[-n:] # MOM指标 x_all = list(zip(sma_data, wma_data, mom_data)) # 样本特征组 y_all = list(klines.close.iloc[i] >= klines.close.iloc[i - 1] for i in list(reversed(range(-1, -n - 1, -1)))) # 样本标签组 # x_all: 大前天指标 前天指标 昨天指标 (今天指标) # y_all: (大前天) 前天 昨天 今天 -明天- # 准备算法需要用到的数据 x_train = x_all[: -1] # 训练数据: 特征 x_predict = x_all[-1] # 预测数据(用本交易日的指标预测下一交易日的涨跌) y_train = y_all[1:] # 训练数据: 标签 (去掉第一个数据后让其与指标隔一位对齐(例如: 昨天的特征 -> 对应预测今天的涨跌标签)) return x_train, y_train, x_predict predictions = [] # 用于记录每次的预测结果(在每个交易日收盘时用收盘数据预测下一交易日的涨跌,并记录在此列表里) api = TqApi(backtest=TqBacktest(start_dt=datetime.date(2018, 7, 2), end_dt=datetime.date(2018, 9, 26))) quote = api.get_quote(symbol) klines = api.get_kline_serial(symbol, duration_seconds=24 * 60 * 60) # 日线 target_pos = TargetPosTask(api, symbol) with closing(api): try: while True: while not api.is_changing(klines.iloc[-1], "datetime"): # 等到达下一个交易日 api.wait_update() while True: api.wait_update() # 在收盘后预测下一交易日的涨跌情况 if api.is_changing(quote, "datetime"): now = datetime.datetime.strptime(quote.datetime, "%Y-%m-%d %H:%M:%S.%f") # 当前quote的时间 # 判断是否到达预定收盘时间: 如果到达 则认为本交易日收盘, 此时预测下一交易日的涨跌情况, 并调整为对应仓位 if now.hour == close_hour and now.minute >= close_minute: # 1- 获取数据 x_train, y_train, x_predict = get_prediction_data(klines, 75) # 参数1: K线, 参数2:需要的数据长度 # 2- 利用机器学习算法预测下一个交易日的涨跌情况 # n_estimators 参数: 选择森林里(决策)树的数目; bootstrap 参数: 选择建立决策树时,是否使用有放回抽样 clf = RandomForestClassifier(n_estimators=30, bootstrap=True) clf.fit(x_train, y_train) # 传入训练数据, 进行参数训练 predictions.append(bool(clf.predict([x_predict]))) # 传入测试数据进行预测, 得到预测的结果 # 3- 进行交易 if predictions[-1] == True: # 如果预测结果为涨: 买入 print(quote.datetime, "预测下一交易日为 涨") target_pos.set_target_volume(10) else: # 如果预测结果为跌: 卖出 print(quote.datetime, "预测下一交易日为 跌") target_pos.set_target_volume(-10) break except BacktestFinished: # 回测结束, 获取预测结果,统计正确率 klines["pre_close"] = klines["close"].shift(1) # 增加 pre_close(上一交易日的收盘价) 字段 klines = klines[-len(predictions) + 1:] # 取出在回测日期内的K线数据 klines["prediction"] = predictions[:-1] # 增加预测的本交易日涨跌情况字段(向后移一个数据目的: 将 本交易日对应下一交易日的涨跌 调整为 本交易日对应本交易日的涨跌) results = (klines["close"] - klines["pre_close"] >= 0) == klines["prediction"] print(klines) print("----回测结束----") print("预测结果正误:\n", results) print("预测结果数目统计: 总计", len(results),"个预测结果") print(pd.value_counts(results)) print("预测的准确率:") print((pd.value_counts(results)[True]) / len(results))点击了解天勤量化软件
关于sklearn随机森林参数的说明 :
https://blog.csdn.net/cherdw/article/details/54971771
策略参考: